TL;DR
Современные LLM умнее, чем когда-либо, но страдают антероградной амнезией: каждая новая сессия начинается с чистого листа. Существующие решения — vector-БД, RAG, встроенные «памяти» в ChatGPT/Cursor, длинные контекстные окна — лечат симптомы, а не причину. Я построил открытую систему долговременной памяти на базе обычных markdown-файлов, протокола MCP и Obsidian, которая работает между разными AI-инструментами, версионируется в git и принадлежит мне, а не вендору. В статье — разбор проблемы, обзор существующих подходов и архитектура решения.
Репозиторий: github.com/Habartru/projecthub — self-host за 5 минут.
Парадокс умнеющего беспамятства
В 2026 году фронтир-модели держат в контексте миллион токенов и больше в одном запросе — в окно легко влезает кодовая база среднего стартапа со всей документацией. Claude Opus 4.7, Gemini 3, GPT-5 рассуждают цепочками на тысячи шагов, пишут код, проектируют системы. Но если вы вчера полдня объясняли AI архитектуру своего проекта, утром вам придётся объяснять её заново. С нуля.
Это не баг. Это фундаментальное свойство трансформеров: контекст — это вход, а не состояние. Между сессиями модель ничего не помнит. И никакое увеличение контекстного окна эту проблему не решает — оно лишь откладывает её на следующий разговор.
Парадокс в том, что чем умнее становится AI, тем заметнее его беспамятство. Глупого ассистента, который путает Python и PHP, не жалко переучивать. А вот когда модель уже в курсе всех 90 ваших проектов, помнит причины архитектурных решений, знает почему email_validator пришлось патчить — и вдруг забывает всё это, — становится больно.
Эта статья — о том, как я решил эту проблему. Не теоретически, а в виде работающего открытого решения, которое прямо сейчас обслуживает всю мою AI-разработку.
Часть 1. Где AI-беспамятство болит сильнее всего
1.1. Кодинг и pair-programming
Симптом: Каждое утро — заново объяснять контекст.
«У нас FastAPI на 8472 порту, Python 3.11, SQLite в
~/Projects/.projecthub.db, 35 unit-тестов запускаются через pytest, фронт single-fileindex.html, наPath.exists()падал PermissionError из-за Python 3.12…»
К концу первой кружки кофе вы уже устали от роли историка собственного проекта. AI готов работать — но не знает, во что лезть.
Хуже того: AI повторно открывает баги, которые вы уже фиксили. Месяц назад вы поняли, что compile_knowledge не пересобирает DAILY_INDEX. Зафиксили, закоммитили. Сегодня AI «находит» этот же баг и предлагает фикс. Час потеряли.
1.2. Знания в команде
Симптом: Ваша Notion / Confluence / Obsidian превращается в свалку.
Когда документации мало — её никто не читает. Когда её много — её тоже никто не читает, потому что не знает где искать. Поиск по ключевым словам выдаёт 200 результатов, из которых релевантных три, но они на 47-й странице.
AI мог бы быть идеальным интерфейсом к корпоративной памяти. Но без структурированной памяти самого AI он либо галлюцинирует, либо постоянно переспрашивает: «уточните, какой именно проект вы имеете в виду?». Контекст приходится постоянно подкармливать вручную.
1.3. Личный workflow
Симптом: AI-ассистент знает, что вы веган, но забывает, что вы Python-разработчик.
Memory-фичи в ChatGPT и аналогах — рандомны и непрозрачны. Они запоминают что хотят и забывают что хотят. Хуже того: их нельзя редактировать структурированно. Если ChatGPT решил, что вы любите Vue, и упорно предлагает Vue вместо React — вы можете только просить «забудь это», но память может вернуться через неделю.
1.4. Долгосрочные проекты
Симптом: Через год возвращаешься к проекту — ноль контекста.
Я открываю ~/Projects/@надо_доделать/uyaz через 8 месяцев. README устарел. Коммит-сообщения скупые. Обсуждения с AI того периода — потеряны (или их нужно искать в архивах чата по 200 страниц). Решения, которые казались очевидными в момент принятия, теперь — загадка.
Проблема не в плохой документации. Проблема в том, что знание возникало в разговоре с AI, но никуда не сохранялось. Это эпистемический провал.
Часть 2. Существующие подходы: разбор полётов
Рассмотрим главные стратегии, которыми сейчас пытаются дать AI память. У каждой — свои сильные стороны и фундаментальные ограничения.
2.1. Большое контекстное окно (brute force)
Идея: Просто скармливать AI всю историю проекта целиком. Современные фронтир-модели — Claude Opus 4.7, Gemini 3, GPT-5 — работают с контекстным окном в 1 миллион токенов и больше. Этого хватит, чтобы засунуть кодовую базу среднего стартапа целиком, со всей документацией и открытыми issue.
Преимущества:
- Простота: не нужна никакая инфраструктура.
- Нет промежуточных слоёв ретривала — модель видит всё.
Недостатки:
- Стоимость: каждый запрос с забитым контекстом — десятки центов. За день активной работы — десятки долларов.
- Attention dilution: исследования показывают, что в длинных контекстах модель «теряется» в середине. Информация на 100K-й позиции усваивается хуже, чем на 5K-й.
- Не персистентно: окно сбрасывается при смене сессии. Через час разговора вы открываете новую вкладку — и история заново.
- Не структурировано: если AI за месяц 200 раз обсуждал ваш проект, в чат-логе нельзя увидеть «итоговое состояние знания».
Вердикт: Большой контекст — это не память. Это очень короткая рабочая память. С таким же успехом можно «лечить» забывчивость, увеличивая объём блокнота.
2.2. RAG (Retrieval Augmented Generation)
Идея: Хранить документы в векторной БД. На каждый запрос делать семантический поиск, подгружать топ-N релевантных кусков, отдавать LLM как контекст.
Стек: Pinecone / Weaviate / Chroma / Qdrant + OpenAI embeddings или локальные модели (BGE, E5).
Преимущества:
- Масштабируется на миллионы документов.
- Дёшево по сравнению с большим контекстом.
- Хорошо работает на однородных корпусах: документация, законы, статьи.
Недостатки:
- Качество эмбеддингов: для специфических доменов (ваш код, ваши решения) общие модели работают плохо. Надо дообучать — а это отдельная задача.
- Семантические провалы: запрос «как мы решили баг с правами доступа» может не найти запись «PermissionError при Path.exists() в Python 3.12», хотя это одно и то же.
- Сложная инфраструктура: vector-БД, pipeline индексации, мониторинг качества retrieval.
- Чёрный ящик: вы не видите, что именно было найдено и почему. Если AI ответил неправильно — отлаживать тяжело.
- Не для активной памяти: RAG хорош для статичных корпусов. Для постоянно меняющегося состояния разработки нужно постоянно переиндексировать.
Вердикт: RAG отлично работает для «корпоративной базы знаний» (10 000 PDF-ок) и плохо работает для «личной памяти разработчика» (100 решений по конкретному проекту).
2.3. Memory-фичи в чат-приложениях
Примеры: ChatGPT Memory, Gemini Memory, Claude Memory.
Идея: Приложение само решает, что запоминать, и подгружает в контекст следующих сессий.
Преимущества:
- Прозрачно для пользователя.
- Работает «из коробки».
Недостатки:
- Чёрный ящик: вы не контролируете что и почему запомнено. Можно посмотреть список, но логика выбора скрыта.
- Нельзя версионировать: нет git, нет diff, нет «откатить, если AI сделал плохие выводы».
- Vendor lock-in: ваша память живёт в OpenAI/Anthropic/Google. Перейти на другую модель — потерять всё.
- Не работает между инструментами: ChatGPT не делится памятью с Cursor, Cursor — с Claude Code.
- Лимиты: размер ограничен, старое вытесняется.
- Для разработки бесполезна: фокус на личных предпочтениях («любит вегетарианскую кухню»), не на проектном контексте.
Вердикт: Хорошо для бытовых чатов. Бесполезно для серьёзной работы.
2.4. Память IDE (Cursor, Windsurf, Copilot)
Идея: IDE индексирует ваш репозиторий и подаёт релевантные куски кода в контекст.
Преимущества:
- Глубокая интеграция с конкретным проектом.
- Понимает структуру кода (AST, символы, ссылки).
- Быстро.
Недостатки:
- Только текущий репозиторий: знания о других проектах не переносятся.
- Только код: решения, обсуждения, причины «почему так» — не сохраняются.
- Между IDE — не работает: переключились с Cursor на Windsurf — начинаете заново.
- Сессионна: открыли новый чат внутри IDE — контекст обнулён.
Вердикт: Незаменима для текущей задачи. Бесполезна для долгосрочной памяти.
2.5. MCP (Model Context Protocol)
Идея: Открытый протокол от Anthropic, который позволяет AI-клиентам подключаться к произвольным «контекстным» серверам — БД, файлам, API.
Это не решение само по себе — это стандарт интерфейса. Сам по себе MCP не реализует память; он даёт способ её подключить.
Почему важно:
- Cross-tool: один MCP-сервер работает с Claude Desktop, Cursor, Windsurf, Zed, AntiGravity и десятком других клиентов.
- Модульно: MCP-серверов можно подключать сколько угодно: один для git, один для базы данных, один для памяти.
- Открыто: спецификация доступна, можно писать свои серверы на любом языке.
Недостаток: MCP — это плита, на которой ещё надо приготовить ужин. Готовых решений для долгосрочной памяти разработчика — пока мало.
2.6. Letta (бывший MemGPT)
Идея: Иерархическая память по аналогии с ОС — «оперативка» (контекст), «диск» (внешнее хранилище), агент сам решает, что куда переносить.
Преимущества:
- Серьёзная исследовательская база, MIT.
- Работает с разными бэкендами.
Недостатки:
- Сложность: требует постоянно работающий API-сервер, отдельный agent runtime.
- Привязка к их платформе: основной use-case — их облачная агентская инфраструктура.
- Не файлово-ориентирована: память живёт внутри их БД, а не в виде читаемых артефактов.
Вердикт: Технически интересно, практически — оверхед.
2.7. Mem0
Идея: Memory layer для LangChain/LlamaIndex. Извлекает факты из разговоров, хранит в vector-БД, инжектит в контекст.
Преимущества:
- Простая интеграция с популярными фреймворками.
- Готовые SDK.
Недостатки:
- Векторное размытие: те же проблемы, что у RAG.
- Не структурированно: нет понятия «проект», «решение», «баг» — только семантические embed-ы.
- Облачный по умолчанию: self-host доступен, но не основной сценарий.
Часть 3. Что упускают все эти решения
Если внимательно посмотреть на список выше, проявляется общая слепая зона. Все существующие подходы решают одну из этих задач — но никогда все сразу:
| Свойство | Большой контекст | RAG | Chat Memory | IDE Memory | Letta | Mem0 |
|---|---|---|---|---|---|---|
| Работает между сессиями | ❌ | ✅ | ✅ | частично | ✅ | ✅ |
| Работает между AI-инструментами | ❌ | ⚠️ | ❌ | ❌ | ❌ | ⚠️ |
| Структурирована (не вектор) | — | ❌ | ❌ | частично | ⚠️ | ❌ |
| Человекочитаема | ✅ | ❌ | частично | ❌ | ❌ | ❌ |
| Версионируется в git | ❌ | ❌ | ❌ | ❌ | ❌ | ❌ |
| Открытые данные (вне вендора) | ✅ | ⚠️ | ❌ | ❌ | ⚠️ | ⚠️ |
| Self-healing / auto-update | — | ❌ | ✅ | ❌ | ✅ | ✅ |
| Можно править руками | ✅ | ⚠️ | ❌ | ❌ | ❌ | ❌ |
Главные не-технические провалы существующих решений:
- Memory ≠ Knowledge. Большинство решений хранят «что было сказано», а не «что было решено». Это разные сущности.
- Нет идентичности проекта. AI не различает «MyApp», который вы делали в 2024, и «MyApp», над которым работаете сейчас. Контекст смешивается.
- Нет UI для человека. Память живёт в БД, к которой у вас нет привычного доступа. Прочитать и поправить — целая история.
- Один инструмент. Cursor пишет в свой файл, Windsurf — в свой, ChatGPT — в свой. Знание фрагментируется.
- Vendor lock-in. Память хранится у поставщика. Сменили модель — потеряли всё.
Я хотел систему, которая решает все эти проблемы одновременно. И построил её.
Часть 4. Решение: ProjectHub + MCP project-context
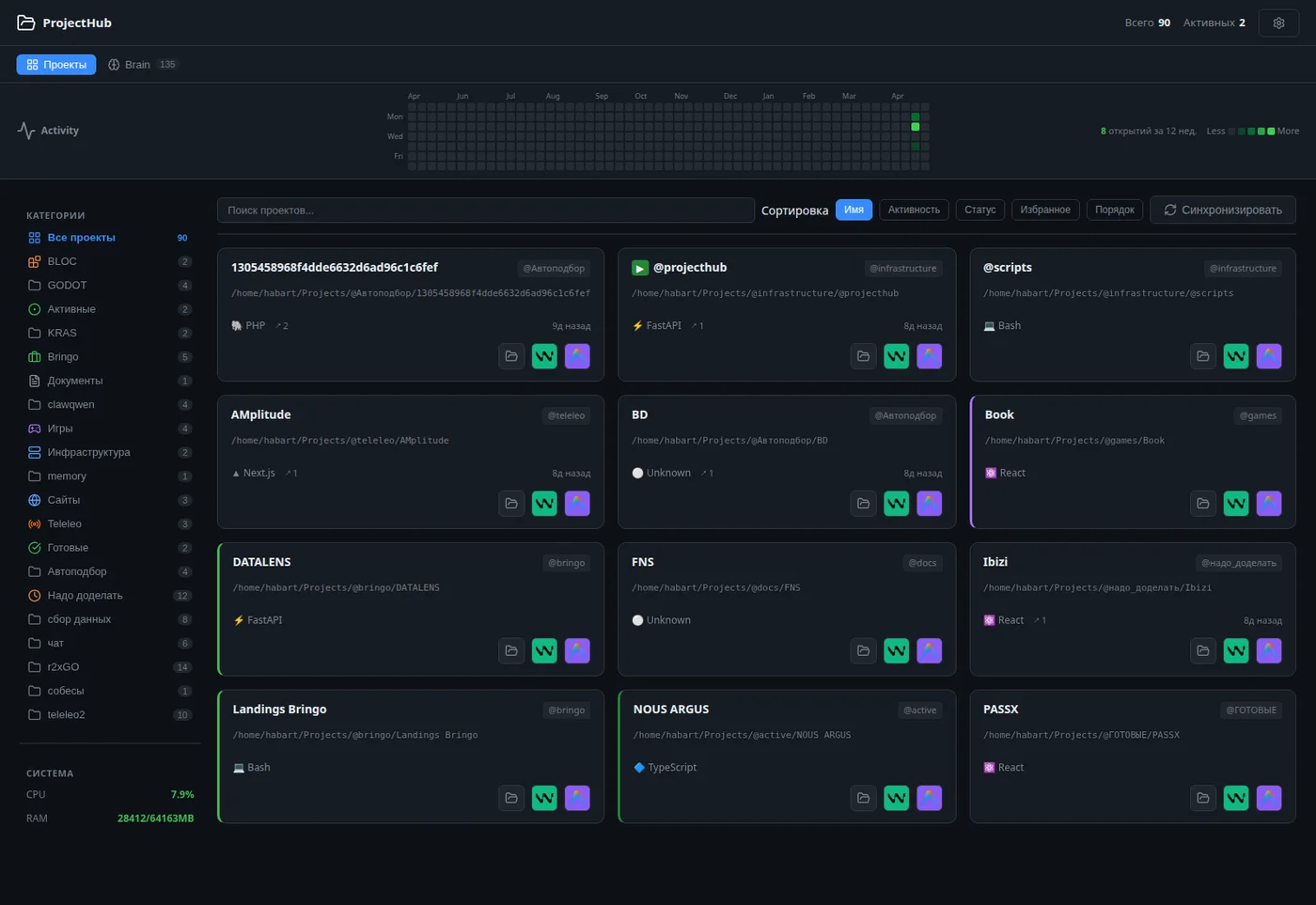
4.1. Философия
Прежде чем код — три принципа.
Принцип 1: Файлы — primary citizen.
Не БД. Не cloud. Не API. Память — это markdown-файлы в git. Любой инструмент мира умеет их читать: AI, Obsidian, VS Code, cat, grep. Любой инструмент будущего — тоже. Файлы переживут любой стек.
Принцип 2: Структура важнее семантики.
Векторный поиск даёт «похожие» куски. Файловая иерархия даёт точный адрес. Не «найди что-то про память», а ~/Projects/@memory/brain/knowledge/projects/projecthub.md. Это 100% relevance, 0% галлюцинаций.
Принцип 3: Человек должен быть в петле. Любую память я могу:
- прочитать в Obsidian,
- отредактировать в любом текстовом редакторе,
- увидеть в графе связей,
- закоммитить в git,
- запушить на GitHub,
- удалить безвозвратно.
Никаких «попроси AI забыть». Открыл файл, удалил абзац, сохранил.
4.2. Архитектура: пять слоёв
graph TD
A[Файловая система<br/>~/Projects/] --> B[SQLite индекс<br/>.projecthub.db]
A --> C[Brain knowledge base<br/>~/Projects/@memory/brain/]
B --> D[ProjectHub Dashboard<br/>FastAPI, 127.0.0.1:8472]
C --> D
C --> E[MCP Server<br/>project-context]
B --> E
E --> F[AI клиенты<br/>Cursor, Windsurf, Claude Code, Zed, AntiGravity]
C --> G[Obsidian<br/>graph + редактор]
D --> H[Веб-UI для человека]Слой 1: Файловая система — единственный источник правды.
~/Projects/
├── @infrastructure/
│ └── @projecthub/ ← сами проекты, обычные git-репы
├── @bringo/
│ └── DATALENS/
├── @memory/
│ └── brain/ ← knowledge base
│ ├── daily/
│ │ ├── 2026-04-27.md
│ │ ├── 2026-04-28.md
│ │ └── 2026-04-29.md
│ └── knowledge/
│ ├── index.md ← Obsidian-индекс
│ └── projects/
│ ├── infrastructure--projecthub.md
│ ├── active--rx2go-platform.md
│ └── надо_доделать--vixai.mdКаждая категория — папка с @. Каждый проект — папка внутри. @memory/brain/ — это собственно AI-память: ежедневные логи и сжатые в постоянные статьи знания по каждому проекту.
Слой 2: SQLite-индекс — ~/Projects/.projecthub.db.
Хранит:
- Список проектов (path, category, name, type, status).
- Activity log (когда что открывали — для heatmap).
- Метаданные (избранное, кастомная сортировка, теги).
SQLite — потому что это файл. Не сервер. Не зависимость. Один .db файл, который можно скопировать на флешку.
Слой 3: ProjectHub Dashboard — FastAPI-приложение на 127.0.0.1:8472.
40 endpoints, 35 unit-тестов, single-file frontend (index.html 100 KB со всем JS/CSS inline). Запускается через systemd, рестартует автоматически, есть /health для мониторинга.
UI даёт человеку:
- Список всех проектов с категориями и статусами.
- GitHub-style activity heatmap (видно, над чем работал последние 12 недель).
- Кнопки запуска: открыть в Cursor, Windsurf, AntiGravity, или просто в файловом менеджере.
- Brain-панель: чтение knowledge-статей.
- Settings: подключение IDE через инжекцию MCP-конфигурации.
Слой 4: MCP-сервер project-context — это и есть «мозг», который видит AI.
11 инструментов, доступных любому MCP-клиенту:
| Tool | Что делает |
|---|---|
list_all_projects | Перечислить все проекты с типами (python/js/rust/…), наличием git/docker/venv |
get_project_details | Полная информация по проекту: путь, ID, стек, README |
get_project_dependencies | Зависимости (requirements.txt / package.json / Cargo.toml) |
get_project_context | Главный инструмент памяти — отдать AI всю накопленную knowledge-статью по проекту |
get_project_history | Git-история + сохранённые инсайты, объединённые хронологически |
read_project_file | Прочитать любой файл проекта (с защитой от .env) |
log_session_insight | Записать новое знание: bug, decision, pattern, gotcha, stack |
compile_knowledge | Слить daily-логи в постоянные статьи и пересобрать индекс |
compare_projects | Сравнить два проекта side-by-side |
get_system_status | Docker, PostgreSQL, общий статус |
get_databases | Список локальных БД |
Слой 5: Obsidian — UI чтения для человека.
~/Projects/@memory/ открывается как vault. Граф связей показывает все проекты, daily-логи, концепты. Wiki-ссылки [[projects/projecthub]] работают нативно. Поиск, теги, бэклинки — всё бесплатно.
4.3. Идентификация: ключевая деталь
Вернёмся к проблеме «AI путает MyApp 2024 и MyApp 2026». Решается она просто и жёстко:
@classmethod
def get_project_id(cls, project_key: str) -> str:
"""Stable hash from project_key. Never collides."""
return hashlib.md5(project_key.encode()).hexdigest()[:8]Каждый проект имеет стабильный ID — md5 от его пути в категориях. infrastructure/@projecthub всегда даёт 599d981c. Этот ID:
- стабилен между сессиями;
- не меняется при синхронизации;
- используется во всех ответах MCP-сервера в виде «ярлыка проекта»;
- виден AI в каждом запросе.
Когда AI читает knowledge-статью, в её заголовке всегда есть:
+------------------------------------------------------------------+
| PROJECT: infrastructure/@projecthub |
| ID: 599d981c |
| Path: ~/Projects/@infrastructure/@projecthub |
+------------------------------------------------------------------+Это банально, но это полностью устраняет смешение контекстов. AI физически не может перепутать проекты, потому что в каждом ответе сервера явно указан ID и путь.
Часть 5. Как это работает в реальной жизни
Сценарий 1: Утро понедельника
Вы открываете Cursor, начинаете чат:
«Возвращаюсь к ProjectHub. Что я делал в пятницу?»
Cursor через MCP вызывает get_project_history(project_name="infrastructure/@projecthub", date_from="2026-04-25"). Сервер отдаёт смешанный таймлайн: git-коммиты + сохранённые инсайты.
Ответ:
2026-04-28 16:35 [insight bug]
Two bugs fixed in a full-system health-check pass:
1. /api/projects/{id}/open-folder did not write to activity_log...
2. MCP list_all_projects crashed with PermissionError on Python 3.12...
2026-04-28 16:36 [git commit]
b1ceb49 fix(backend): log activity_log on /open-folder endpoint
2026-04-28 16:36 [git commit]
23df1f1 fix(mcp): skip unreadable entries when walking project treeAI сразу в курсе: что чинили, почему, какие именно коммиты. За 200 миллисекунд.
Сценарий 2: Поймали редкий баг
В процессе отладки находите хитрый случай: на Python 3.12 Path.exists() теперь бросает PermissionError вместо тихого False. Чините. Говорите AI:
«Запиши инсайт: на Python 3.12 Path.exists() стал бросать PermissionError на EACCES. Чтобы list_all_projects не падал, обернули в try/except OSError. Закоммитили 23df1f1.»
AI вызывает log_session_insight:
log_session_insight(
project_name="infrastructure/@projecthub",
insight_type="bug",
content="Python 3.12 changed Path.exists() to raise PermissionError on EACCES (earlier versions returned False). Fixed in 23df1f1 by wrapping is_dir() and (entry/'pyvenv.cfg').exists() in try/except OSError blocks.",
tags=["python3.12", "permissions", "mcp"]
)В фоне:
- Запись добавляется в
~/Projects/@memory/brain/daily/2026-04-29.md. - При следующем
compile_knowledgeинсайт мёрджится в постоянную статьюknowledge/projects/infrastructure--@projecthub.md. - Obsidian-индекс пересобирается — daily/2026-04-29 появляется в графе.
Через месяц, когда я снова столкнусь с похожей проблемой, AI прочитает эту статью и сразу скажет: «Это известная проблема с Python 3.12, мы её чинили в 23df1f1, вот фикс».
Сценарий 3: Возвращение к проекту через 8 месяцев
Открываете заброшенный проект надо_доделать/uyaz. Говорите:
«Что это за проект? Что было сделано? Что осталось?»
AI вызывает get_project_context("надо_доделать/uyaz"). Сервер отдаёт постоянную статью со всеми сохранёнными инсайтами, плюс git-историю.
Через 30 секунд у AI (и у вас) полная картина: цель, выбранный стек, ключевые архитектурные решения, причины этих решений, известные баги, открытые вопросы. Без чтения 50 страниц README и расшифровки коммитов.
Это и есть долговременная память разработчика, доступная любому AI-инструменту.
Часть 6. Почему это работает иначе
6.1. Структурированная память против векторного «болота»
Классический RAG работает на семантической близости. Это статистический процесс: «найди абзацы, похожие на запрос». Точность = 70–85% даже на хороших корпусах.
Здесь — прямая адресация. AI спрашивает «что у нас есть про проджект X», сервер отдаёт именно статью про X. Точность = 100%, потому что это не поиск, а чтение по индексу.
6.2. Self-healing index
Любая система памяти со временем расходится с реальностью. Файлы добавляются, статьи редактируются, индекс отстаёт.
Решение: compile_knowledge всегда пересобирает индекс из файлов на диске. Не из своего кэша. Не из БД. Из реальных .md. Если кто-то добавил daily-лог вручную — он автоматически попадёт в Obsidian-граф при следующем вызове compile.
def update_index():
"""Rebuild index.md from all project, concept, and daily-log files.
Every section is rebuilt from the actual files on disk so daily logs
and project articles created outside of compile_knowledge never end
up as orphan nodes in Obsidian's graph.
"""
# ... сканирует knowledge/projects/, knowledge/concepts/, daily/
# ... перезаписывает три секции в index.md6.3. Cross-tool взаимодействие
Один MCP-сервер — все клиенты получают одну и ту же память. Подтверждено в моей системе:
| IDE | Установлен | MCP подключён |
|---|---|---|
| Windsurf | ✅ | ✅ |
| Qoder | ✅ | ✅ |
| AntiGravity | ✅ | ✅ |
| Claude Code | ✅ | (ручное подключение) |
| Cursor | — | (по запросу) |
| Zed | ✅ | (ручное подключение) |
Cursor в один день, Windsurf на следующий, Claude Desktop в четверг — все читают один и тот же knowledge base. Все пишут в один и тот же daily-лог. Никаких силосов.
6.4. Версионирование
~/Projects/@memory/brain/ — это git-репозиторий. Каждое изменение памяти можно:
- увидеть в
git log, - сравнить через
git diff, - откатить через
git revert, - запушить в приватный репо для бэкапа,
- расшарить с командой (когда понадобится).
В существующих memory-фичах это попросту невозможно.
6.5. Прозрачность для пользователя
Вот что произошло, когда я спросил AI «расскажи о наших последних изменениях в ProjectHub»:
+------------------------------------------------------------------+
| PROJECT: infrastructure/@projecthub |
| ID: 599d981c |
| Path: ~/Projects/@infrastructure/@projecthub |
| Stack: python |
+------------------------------------------------------------------+
# История решений
## [2026-04-29 16:35] bug — feat: /health endpoint, retention, hardening
Quick-wins audit pass:
- /health and /api/health — lightweight liveness probe...
- Activity log retention — _prune_activity_log() drops rows >730 days...
- Hardened systemd unit: Restart=always, MemoryMax=512M...Это читаемо человеком. Я могу открыть тот же файл в Obsidian, прочитать, поправить опечатку, добавить комментарий. Это не «AI вспомнил» — это «AI прочитал записанное».
Часть 7. Технические детали для скептиков
Стек:
- Backend: Python 3.11, FastAPI, Pydantic v2, SQLite
- MCP server: Python 3.11, протокол MCP
- Frontend: vanilla JS, single-file
index.html - Knowledge: markdown + Obsidian
- Auto-start: systemd user service
- Тесты: pytest, 35 кейсов, 0.6 секунды
Производительность:
list_all_projectsдля 90 проектов с детектом стека и venv: ~150 мс.get_project_contextдля проекта с 50 инсайтами: ~30 мс.compile_knowledgeпересборка индекса: ~80 мс.
Безопасность:
- Bind только на 127.0.0.1 (никаких внешних подключений).
- CORS жёстко ограничен localhost.
.envфайлы автоматически отфильтрованы из чтения через MCP.- systemd:
MemoryMax=512M,TasksMax=64,PrivateTmp=true,LockPersonality=true. /healthendpoint для health-check.
Ресурсы:
- В покое: ~52 MB RAM, <0.1% CPU.
- БД на 90 проектов: ~80 KB.
- Knowledge base со 100 инсайтами: ~150 KB.
Это не тяжёлое решение. Запускается на любом ноутбуке.
Часть 8. Сравнительная таблица
| Решение | Сессии+ | Cross-tool | Структура | Чел.-чит. | Git | Open data | Self-heal |
|---|---|---|---|---|---|---|---|
| Большой контекст | ❌ | — | — | ✅ | — | ✅ | — |
| RAG (Pinecone и др.) | ✅ | ⚠️ | ❌ | ❌ | ❌ | ⚠️ | ❌ |
| ChatGPT Memory | ✅ | ❌ | ❌ | ⚠️ | ❌ | ❌ | ✅ |
| Cursor / Windsurf Memory | ⚠️ | ❌ | ⚠️ | ❌ | ❌ | ❌ | ❌ |
| Letta / MemGPT | ✅ | ⚠️ | ⚠️ | ❌ | ❌ | ⚠️ | ✅ |
| Mem0 | ✅ | ⚠️ | ❌ | ❌ | ❌ | ⚠️ | ✅ |
| ProjectHub + MCP | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ |
Не утверждаю, что у меня перфектное решение для всех ниш. Например, для корпоративной базы из 100 000 PDF-документов RAG лучше. Но для личной памяти разработчика, работающего с десятками AI-инструментов, — у меня в одной таблице семь зелёных галочек, у других — максимум четыре с натяжкой.
Часть 9. Что не решено и куда дальше
Известные ограничения
Шаринг между людьми. Сейчас knowledge base — личная. Чтобы расшарить с командой, нужно вручную push’ить git-репо. Хотел бы автоматизированный sync с разрешением конфликтов, но это уже отдельный продукт.
Автоматическое суммирование длинных тредов. Если AI обсуждает с вами 4 часа и не вызывает log_session_insight — знание не сохранится. Нужен агент, который мониторит и вытаскивает важное автоматически. Прототип в работе.
Conflict resolution. Когда два разных AI-клиента одновременно пишут инсайты по одному проекту — теоретически возможен race condition в SQLite. На практике пока не ловил.
Качество поиска по тегам. Сейчас — простой substring match. Хочется semantic ranking, чтобы запрос «как мы боролись с памятью» находил инсайты с тегами optimization, oom, memory-leak.
Roadmap
- Q2 2026: автоматический summarizer чатов (background-агент через cron + heartbeat).
- Q3 2026: team mode — push knowledge base в общий приватный репо с merge-стратегиями.
- Q4 2026: semantic search поверх файловой структуры (гибрид: точная адресация + векторный ранкинг по тегам).
- 2027: интеграция с issue-трекерами (GitHub, GitLab, Jira) — двусторонний sync.
Часть 10. Философия
Хорошая память — это не feature. Это архитектура.
В индустрии AI принято считать, что память — это что-то, что добавляется поверх. «Возьмём LLM, прикрутим vector-БД, готово». Я утверждаю, что это обратное прикладывание задачи.
Память — это первый класс гражданства разработчика. Не файлы и БД-схемы должны крутиться вокруг LLM, а LLM должен прийти в готовую файловую структуру и читать её, как любой нормальный инструмент: cat, IDE, человек.
Open data > Closed memory. Любая память, которая живёт у вендора, — потенциально потерянная. Любая память, которая живёт у вас на диске в open-формате, — навсегда ваша.
Структура > семантика. Векторный поиск — это «авось найдётся». Файловая иерархия — это «гарантированно найдётся». В рабочем окружении гарантии важнее «магии».
Простота > сложность. Markdown в git побеждает Pinecone-кластер не потому, что лучше технически. А потому, что дешевле в эксплуатации: ноль зависимостей, ноль ежемесячных счетов, ноль рисков, что сервис закроется.
Эпилог: попробуйте сами
Весь код открыт. Установка — одна команда:
curl -fsSL https://raw.githubusercontent.com/Habartru/projecthub/main/install.sh | bashПосле этого:
- Откроется
http://127.0.0.1:8472— список ваших проектов. - В Settings → Connect IDE инжектируете MCP-сервер в Cursor / Windsurf / Claude Code.
- Спрашиваете AI:
«какие у меня есть проекты?»— получаете полный список с типами и статусами. - Начинаете работать — AI постепенно записывает инсайты в
~/Projects/@memory/brain/. - Через неделю открываете Obsidian — видите граф своих знаний.
Через месяц вы поймёте, что AI больше не задаёт глупых вопросов про ваш проект. Он уже всё знает. И помнит.
Репозиторий: github.com/Habartru/projecthub Лицензия: MIT — берите, форкайте, улучшайте. Контакт: обсуждения и вопросы — в Issues.
Если статья была полезна — расскажите коллеге, у которого AI каждое утро забывает контекст. Это лечится.
Артём Ротганк, AI/ML инженер, апрель 2026.


